Debugging Validator Downtime in DPoS Networks: A Beginner’s Guide to Node Stability
If you are running a validator in a Delegated Proof of Stake (DPoS) network, you already know that uptime is everything. When your validator goes offline, even for a few minutes, you can lose rewards, votes, and sometimes even your reputation. Validator downtime means your node is not doing its job. It is not validating blocks, not producing new ones, and not helping the network stay secure.
- What Causes Validator Downtime in DPoS
- Network Problems
- Hardware and Software Crashes
- Configuration Mistakes
- Governance and Voting Delays
- Tools and Metrics for Monitoring Validator Uptime
- Common Debugging Steps for Validator Downtime
- Step 1: Check Your Logs
- Step 2: Restart and Resync the Node
- Step 3: Verify Private Keys and Signer Setup
- Step 4: Test Network Latency and Bandwidth
- Preventing Future Validator Downtime
- Schedule Regular Backups
- Use Redundant Nodes or Failover Systems
- Keep Software and Dependencies Updated
- Participate in Testnets and Simulations
- How Downtime Affects Rewards and Reputation
- Case Study: A Validator Recovery Example
- Best Practices for Validator Reliability
- Monitor 24/7, Don’t Guess
- Keep Backups in More Than One Place
- Stay Active in the Validator Community
- Document Your Setup and Changes
- Simulate Failure Regularly
- Conclusion
- FAQs for A Beginner’s Guide to Node Stability, Validator Downtime in DPoS
- What does validator downtime mean in a DPoS network?
- Why does validator downtime happen?
- How do I know if my validator is down?
- What is the best way to debug validator downtime?
- How does downtime affect validator rewards and votes?
- How can I prevent validator downtime in the future?
- Can validators recover their reputation after long downtime?
- Glossary of Key Terms
DPoS networks like EOS, Tron, or BitShares depend on a team of elected validators (or delegates) to maintain the network. Token holders vote on each validator. So when your node goes offline, someone else may take your place as a validator. This is why keeping validators online is like keeping your store open. If you leave, your customer will be taken by someone else!
Validator downtime can happen for many reasons. Sometimes it’s a small thing like a software update that failed. Other times, it could be network lag, incorrect key configuration, or a backup power array. The key consideration is how quickly you can identify the root cause of the failure and restore the validator. Debugging downtime is not just about restarting your node; it’s about figuring out why the downtime happened in the first place, before you were alerted to it.
Most DPoS chains currently operate monitoring dashboards that provide real-time uptime stats, block history, and peer status. These tools only provide data on what is wrong, not how to fix it. This guide is all about learning a simple way to debug validator downtime and prevent the same issues from recurring in the future in DPoS.
ALSO READ: A Beginner’s Guide: Building a Fair Token Distribution System in DPoS Networks
What Causes Validator Downtime in DPoS
Validator downtime can come from a mix of network, software, or human mistakes in DPoS. Even professional validator teams face this sometimes. The key is learning to notice the signs early.
Network Problems
Network problems in DPoS are the number one reason for downtime. If your validator can’t talk to other nodes, it stops producing blocks. This can happen if your internet is too slow, your ports are closed, or your node loses connection to peers.
For example, if the ping between your node and others is too high, it means your node is slow to answer. That delay causes it to miss its turn in the validation round. According to Wang et al. (2022), even a few missed rounds can lower your score in credit-based DPoS systems. Here’s a simple comparison of common network issues and what they cause:
| Cause | Description | Result |
| Slow Internet | Node fails to connect to peers on time | Missed blocks |
| Firewall Blocks | Port 26656 or similar is closed | Node unreachable |
| DNS Errors | Node can’t find peer addresses | Offline status |
Network issues can be tricky because they don’t always appear right away. Your node might look fine in logs, but still not produce blocks. That’s why monitoring latency, bandwidth, and peer connections is important.
Hardware and Software Crashes
Validators need good hardware to stay online. If your machine overheats or runs out of memory, it will crash. Even cloud-based servers face downtime when CPU or RAM usage spikes. Sometimes, it’s not even your fault; a cloud provider might restart or throttle your instance. Outdated node software is another hidden cause. DPoS systems update often to fix bugs or adjust parameters. If your version is old in DPoS, your node may desync from the chain and stop validating.
Let’s say your validator is using version 1.2.1 while the network upgraded to 1.3.0. The new version might change how blocks are signed, so your node will just keep failing quietly. You’ll see “block signature rejected” in your logs. That’s how small update delays can lead to downtime. Keeping up with official validator channels helps here. Teams often post upgrade alerts in advance, and it’s safer to test updates on a secondary node first. As Hu et al. (2021) pointed out, update coordination is a common weak spot in decentralized validator networks.
Configuration Mistakes
Configuration errors are frequent, particularly for new validators. It could be a minor misconfiguration in DPoS, such as using the wrong private key file or setting the wrong path, or it may involve forgetting to open a port. These errors will not crash your node, but make it inoperative. It will sit there and be fine, but produce no block.
For example, if your config file has the wrong “moniker” or node ID, other peers may not recognize your validator correctly. Or if your time is not synced with the global clock (NTP), your block signatures may get rejected.
One validator once shared that a single missing line in their config file kept them offline for two days. The node was running, logs were clean, but it was never participating in consensus. It turned out the signing key path was pointing to an old folder. So debugging sometimes is like finding a missing comma in a big paragraph.
Governance and Voting Delays
Sometimes, downtime is not because of a technical failure but due to governance. DPoS validators must also vote on proposals, upgrade decisions, and delegate shifts. When validators in DPoS stop voting or communicating, they can lose trust and delegation. Some networks even auto-remove inactive validators.
This “soft downtime” is just as dangerous as real downtime. The node might be online, but if the validator does not participate in governance rounds, it loses its position over time. Li et al. (2023) noted that validator enthusiasm and participation directly affect their credit scores in community-driven DPoS systems. So staying active in votes, proposals, and community discussions is part of uptime too. You are not just running a node; you are part of the governance process that keeps the network fair.
Tools and Metrics for Monitoring Validator Uptime
Debugging downtime becomes much easier when you know how to monitor your node correctly. Modern DPoS chains have many tools to track performance and uptime. Some tools are built into the blockchain explorer, while others are external monitoring dashboards.
For DPoS beginners, simple tools like Pingdom or UptimeRobot can alert you when your node goes offline. Advanced operators prefer Grafana and Prometheus because they collect real-time metrics like CPU use, peer count, and block height. According to Li et al. (2023), networks using credit-based monitoring systems improve validator accountability by linking performance to visible metrics. Here’s a small table showing common monitoring tools and what they do:
| Tool Name | What It Checks | Difficulty Level |
| Grafana | CPU, memory, uptime graphs | Medium |
| Pingdom | External ping checks | Easy |
| Chain Explorer | Block activity and vote status | Easy |
| Prometheus | Node metrics and alerts | Advanced |
When debugging validator downtime in DPoS, metrics like “missed blocks,” “peer connections,” and “latency time” are your best indicators. If your node is missing many blocks but peer count is high, that usually means an internal issue. If both are low, it’s likely a network or sync problem.
Another good practice is checking “heartbeat” signals. Many validators send heartbeat data to external dashboards that confirm if the node is alive. If the heartbeat stops, you know it’s time to log in and inspect what’s wrong.
ALSO READ: How DPoS Remains the Backbone of Blockchain Governance in the Layer 2 Era
You can also calculate uptime on your own. Most validators strive for 99.9% uptime, which provides for 40 minutes of downtime in a month. If a validator has uptime below 95%, they will be demoted in rank and may have their delegations reduced or rewards removed. Use the following table as a rough way to see how uptime affects a validator’s performance.
| Uptime | Node Health | Reward Retained |
| 99.9% | Excellent | 100% |
| 98% | Good | 85% |
| 95% | Average | 60% |
| Below 90% | Poor | 0% |
Keeping your validator monitored is like checking your car’s dashboard while driving. The sooner you see a warning light, the easier it is to prevent bigger problems later. As Cowen (2020) explained, decentralized governance depends not only on code but also on how responsible and visible the participants are. The same applies to validators; visibility is trust.
Common Debugging Steps for Validator Downtime
When your validator suddenly stops producing blocks, the first thing to do is not to panic. Downtime happens even to top validators. What matters most is how you handle it. Debugging means finding where the problem started and fixing it fast.
There’s no single rule that fits all networks, but most DPoS validators follow these same steps when their node goes offline. Let’s go through them one by one in plain words.
Step 1: Check Your Logs
Logs are like your validator’s diary in DPoS. They record everything your node does, every connection it makes, every error it hits. When downtime starts, checking logs is always the first step. Most DPoS nodes save logs in files like app.log or node.log. When you open it, look for lines like “missed block,” “connection refused,” or “timeout.” These messages tell you what’s wrong. Sometimes, you might see something like this:
ERROR [Validator] missed block at height 350912 (peer timeout)
That means your node didn’t respond fast enough to other peers. Or maybe you’ll see:
FATAL [Consensus] failed to sign block (key not found)
This means your key file is missing or in the wrong folder. Logs don’t lie. They’re your best friend when debugging validator downtime. As Li et al. (2023) discussed, validator trust is linked to how fast and accurately they respond to such operational failures.
Step 2: Restart and Resync the Node
After you check the logs and find no big damage, restarting the node helps a lot. Many times, a validator just gets stuck syncing and needs a push. Restarting clears memory, closes stuck connections, and resets the process.
When restarting doesn’t fix it, resyncing might be needed. This means deleting your local chain data and downloading the full blockchain again from peers. It takes time, but it’s worth it when your node is badly behind.
| Problem | Fix | Time Needed |
| Node stuck syncing | Restart and reload database | 10–30 min |
| Version mismatch | Update binaries | 15 min |
| Peer rejection | Reset connections and rejoin peers | 5–10 min |
If your validator is falling behind block height for more than an hour, it’s safer to resync. Some validators also run a “sentinel” node, a backup that keeps the data ready so if one crashes, another can replace it quickly (Hu et al., 2021). Remember to always stop your node before doing major fixes. Restarting without stopping correctly can corrupt files. It’s like unplugging your computer while saving a document.
Step 3: Verify Private Keys and Signer Setup
Validators sign every block they produce. If your private key or signer file is broken, the node can’t sign and gets skipped. This is another common reason for downtime. Sometimes, a validator’s key file moves during a system update or a permissions change after a reboot. When that happens, your node may run fine but never actually sign blocks.
To check this, look in your configuration folder for the key file path. If it looks wrong or empty, fix it and restart. You can test signing locally to make sure your validator responds. Always back up your key before changing anything.
Losing a validator key can mean losing your whole identity in the network. In DPoS, every validator has a reputation score linked to that key. When it breaks, the score resets. Wang et al. (2022) found that key rotation errors were a top cause of unplanned validator downtime across multiple blockchain tests.
Step 4: Test Network Latency and Bandwidth
Your validator needs to talk fast with other peers. High latency (delay) makes your validator slow in producing blocks. You can check this using simple commands like ping or traceroute. If your ping is over 200ms or you have packet loss, it’s time to switch servers or ISPs. Validators with poor latency often get fewer votes because they miss more blocks.
Also, watch your upload speed. DPoS nodes share lots of data, block headers, votes, and transactions. Slow upload means slow consensus. Some validators even set up regional mirrors or relay nodes to improve speed. Li et al. (2023) suggest that improving node responsiveness improves not just performance but also voting confidence in DPoS systems.
Preventing Future Validator Downtime
Fixing downtime is good, but preventing it is better. Validators who stay online all year earn more trust and rewards. Keeping your node stable means preparing for both technical and environmental problems before they happen.
Schedule Regular Backups
Every DPoS validator should have a backup plan. Back up your private keys, configuration files, and wallet data. Even better, use snapshots of your node’s data every few hours. That way, if your system crashes, you don’t have to download the whole blockchain again.
Backups can be stored on another server, a USB, or cloud storage. Just make sure they are encrypted. A lost or hacked backup is as bad as losing your live node. Even small validators can use simple scripts that copy data every 6 or 12 hours. Many top operators do this automatically using cron jobs or monitoring bots.
Use Redundant Nodes or Failover Systems
One of the smartest things validators can do is set up redundancy. That means having a second or even third node ready to take over if your main one goes down.
Redundant setups reduce downtime from hours to just a few seconds. Some projects even use load balancers that redirect traffic automatically to backup nodes.
| Setup Type | Cost | Reliability | Best For |
| Single Node | Low | Medium | Hobby users |
| Dual Node Failover | Medium | High | Semi-professional |
| Full Cluster | High | Very High | Professional validators |
If your validator is small and on a budget, a simple dual-node system is enough. One acts as the active validator, the other stays in standby mode and takes over during failure (Wang et al., 2022).
Keep Software and Dependencies Updated
Always stay up to date. Outdated node software or dependencies cause most downtime events. Projects release updates to fix bugs, improve sync speed, and close security holes. Before updating, always test on a secondary node or a testnet. Never update directly on your main validator unless you are sure the update works fine. Hu et al. (2021) reported that around 40 percent of validator outages were due to bad version updates.
You should also update the server’s OS, libraries, and Docker containers if you use them. An outdated Linux package can cause network incompatibility even when the blockchain software is new.
Participate in Testnets and Simulations
Many DPoS projects launch testnets before main updates. These are playgrounds where validators can test new versions, see logs, and practice without losing rewards. Participating in testnets not only teaches you debugging skills but also gives you a better reputation in the validator community.
ALSO READ: Why Switch from PoS to DPoS Staking in 2025
Validators active on testnets are often the first to spot and report bugs, which builds trust (Li et al., 2023). You can even simulate downtime by turning off your node for an hour and bringing it back up. Practicing recovery steps prepares you for real situations later.
How Downtime Affects Rewards and Reputation
In Delegated Proof of Stake, uptime is everything. The higher your uptime, the more trust you earn from delegators and the more rewards you receive. When you go offline, your earnings drop, and sometimes, your votes do too.
DPoS systems measure uptime by tracking missed blocks. Each missed block lowers your reliability score. Some networks automatically slash rewards or remove validators who miss too many blocks. Here’s a simple view of how uptime connects to your rewards:
| Uptime | Reward Retained | Risk of Slashing |
| 99.9% | 100% | None |
| 98% | 85% | Low |
| 95% | 60% | Medium |
| Below 90% | 0% | High |
For small validators, a few hours of downtime can mean losing delegation votes. Once delegators see your node marked “offline,” they may move their tokens to others. Validators also have “credit scores” or “trust scores.” These scores come from their performance history. If your node is often down, the score drops. In some systems, it takes weeks of perfect uptime to rebuild that score (Li et al., 2023).
Downtime also affects governance. Validators with low reliability may lose voting rights or influence. This makes it harder for them to propose network changes or get elected again. As Cowen (2020) pointed out, governance systems depend on credibility. In DPoS, credibility comes from uptime. If your validator stays strong, responsive, and transparent, the community sees you as reliable. If not, it’s easy to lose trust fast.
In short, keeping your validator online is not just about making money, it’s about staying respected in the network. Each block you validate adds to your reputation, and each missed block takes a little away.
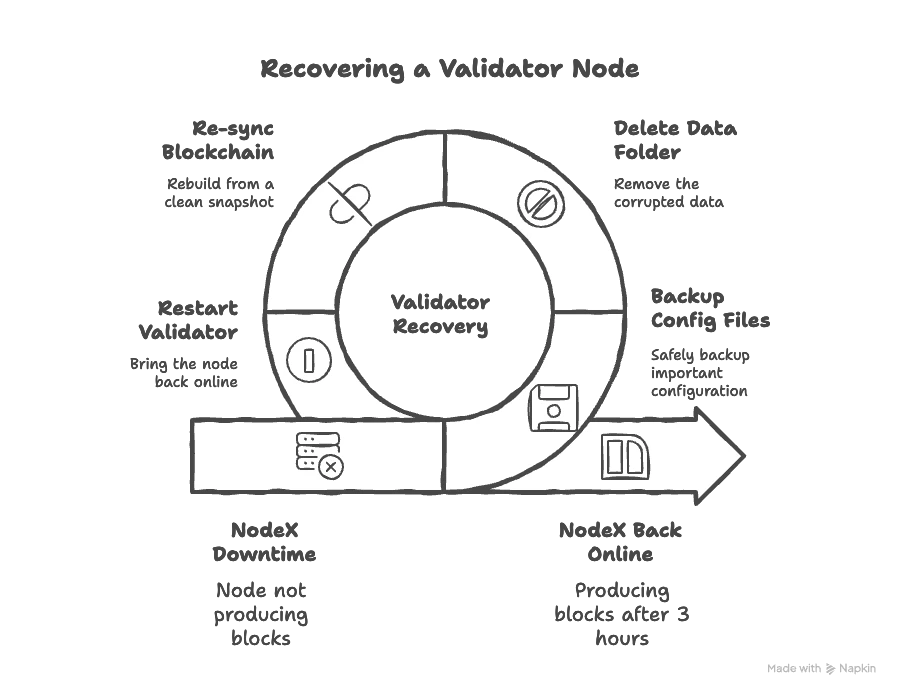
Case Study: A Validator Recovery Example
A validator called NodeX was running on a small DPoS network. It had good uptime for months, but suddenly went offline for almost four hours. The operator noticed it when the block explorer showed “Node not producing.” At first, they thought it was a network issue. Ping was fine, and the server dashboard showed the machine was running. But when they opened the logs, the message said:
[ERROR] Failed to commit block: database corruption detected
The node’s blockchain database got corrupted after a disk failure. The validator tried restarting, but kept stopping again. The operator took the following steps:
- Backed up the config and key files safely
- Deleted the broken data folder
- Re-synced the blockchain from a snapshot
- Restarted the validator and checked peers
After about 3 hours, the node came back online. The operator also added a second backup node after this event to make sure it won’t happen again.
| Problem | Cause | Fix Applied | Result |
| NodeX downtime | Database corrupted | Rebuilt from a snapshot | Back online in 3 hrs |
This simple example shows how most downtime issues can be solved with calm debugging. It’s not always about complex code. Sometimes, it’s just about reading logs carefully and rebuilding with clean data. A study by Li et al. (2023) explains that DPoS systems improve stability when validators combine technical fixes with consistent participation. Meaning, being fast to react matters as much as running good hardware.
Downtime also taught NodeX’s operator another lesson: always back up the validator folder and store snapshots every 24 hours. One small mistake can cost rewards and trust, but good habits can save both.
Best Practices for Validator Reliability
Debugging downtime is a skill, but staying reliable is a lifestyle. Every validator who wants to last long in a DPoS network needs to follow certain habits. These habits make sure your node stays strong and your name stays trusted.
Monitor 24/7, Don’t Guess
A validator is like a server that never sleeps in DPoS. You need constant monitoring. Using alert systems like Grafana or UptimeRobot can help. When your node drops even for a minute, you get a notification by email or phone. Some validators also use Telegram bots that send daily status reports. You can see how many blocks were missed, how fast the node is, and when the last block was signed. It takes only a few minutes to set up, but it saves hours of losses.
As Hu et al. (2021) mentioned, automated monitoring greatly reduces response times in blockchain node maintenance. Validators who rely on automation recover faster than those who check manually.
Keep Backups in More Than One Place
Never keep all backups on the same server. If your server crashes or gets hacked, all backups go with it. Using both a local backup and a cloud copy is much safer. Even something as simple as Google Drive or Dropbox can help small validators. For large ones, off-site backups or S3 buckets work better.
A small validator on a community DPoS network once lost all keys due to a power outage that fried both the main and backup drives. They had no copy elsewhere and had to start fresh. This happens more often than you’d think.
Stay Active in the Validator Community
Being part of the community helps you spot issues faster. Validators in DPoS often share known bugs, fix guides, and new security alerts. If one validator faces an issue, others usually experience it too.
Some DPoS networks also have “validator councils” that discuss upgrades and coordinate maintenance times. Joining them keeps you informed. Wang et al. (2022) said validators who actively share and report bugs improve overall network health, which in turn builds community trust. Even a quick message like “anyone else seeing block sync delay?” in the chat can save you hours of frustration.
Document Your Setup and Changes
Most downtime in DPoS happens after updates or changes in DPoS. If you don’t document what you changed, you can’t reverse it when things break. Keep a simple note file that logs every update, config edit, or restart. When something goes wrong, you can just look back and see what changed last. It’s a simple trick that helps even professionals.
For example, one validator on a testnet upgraded Docker without noting it, which broke its node dependencies. It took hours to realize that was the cause. Documentation could’ve saved that time easily.
ALSO READ: DPoS Voting Explained: How Does On-Chain Governance Work?
Simulate Failure Regularly
It might sound strange, but intentionally testing failure helps you learn faster in DPoS. Try restarting your node or disconnecting it for a few minutes to see how fast it recovers. These small simulations tell you if your backups, alerts, and failover systems actually work. If they don’t, you’ll know before a real crash happens.
As Li et al. (2023) pointed out, simulation-based validator training improves readiness and reduces downtime impact. DPoS networks benefit most when validators learn through testing, not trial and error during real crises.
Conclusion
Validator downtime is one of those things every DPoS participant fears but can’t completely avoid. The good news is that with simple habits and quick debugging, you can keep downtime low and trust high. Running a validator is more than just turning on a computer. It’s a balance of monitoring, updating, and communicating. If your node goes offline, you don’t just lose tokens; you lose visibility in the community. But if you recover fast and share lessons, you gain respect.
Every validator should aim for at least 99.9% uptime in DPoS, not just for the rewards but also for the trust it brings. Networks grow stronger when validators stay honest, active, and available. In short, debugging validator downtime isn’t rocket science. It’s about keeping calm, checking the basics, and staying connected with your peers. The more you practice it, the easier it gets.
FAQs for A Beginner’s Guide to Node Stability, Validator Downtime in DPoS
What does validator downtime mean in a DPoS network?
Validator downtime means your node goes offline or stops producing blocks in a Delegated Proof of Stake (DPoS) network. When that happens, the validator can’t confirm transactions, and it loses both rewards and reputation. The longer the downtime, the higher the penalty.
Why does validator downtime happen?
Downtime can happen because of a bad internet connection, server crashes, wrong configuration, outdated software, or corrupted data. Sometimes it’s human error, like using the wrong private key or missing a network upgrade. In DPoS systems, even a few minutes offline can hurt your validator score.
How do I know if my validator is down?
You can check your validator’s status through block explorers, Grafana dashboards, or monitoring tools like UptimeRobot or Pingdom in DPoS. If you see “missed blocks,” “peer timeout,” or “node not responding,” it means your validator is likely down or lagging behind the latest block height.
What is the best way to debug validator downtime?
Start with the basics. Check your logs first; they show why your node failed. Then restart your node, verify your key files, and test network connectivity. If your node is too far behind, resync it with the blockchain. This process solves 80 percent of downtime issues.
How does downtime affect validator rewards and votes?
In most DPoS systems, validators earn rewards based on uptime. Missing blocks reduces both token income and voting reputation. If your uptime falls below 95 percent, delegators may stop voting for you. Networks like EOS or Tron track validator reliability in real-time, so staying online matters.
How can I prevent validator downtime in the future?
Always keep backups, update your node software regularly, and use alert systems to monitor uptime. Some validators use redundant or failover nodes that take over if the main one goes offline. Participating in testnets also helps you prepare for upgrades safely (Hu et al., 2021).
Can validators recover their reputation after long downtime?
Yes, but it takes time. Once your node is stable again, you need to maintain perfect uptime for several weeks. Over time, your credit score improves, and delegators may start trusting you again. Consistency is key; one stable month can undo weeks of poor performance.
Glossary of Key Terms
Validator – A node in a blockchain that helps confirm and produce blocks. In DPoS systems, validators are chosen by voting.
DPoS (Delegated Proof of Stake) – A consensus system where token holders elect a few validators to produce blocks and secure the network.
Downtime – When a validator or node is offline and not producing blocks.
Node – A computer that connects to and maintains a blockchain network.
Block Production – The process of creating new blocks on the blockchain by validators.
Resyncing – Re-downloading blockchain data when the local copy becomes outdated or corrupted.
Failover Node – A backup node that takes over when the main validator fails.
Uptime – The percentage of time a node stays online and active.
Slashing – A penalty in blockchain systems for bad behavior like downtime or malicious activity.
Credit Score (Validator Reputation) – A rating based on how reliable and active a validator has been over time.